In software engineering circles, there is a common adage: “code is read more than it is written”. But this is not the whole picture! Code is skimmed more than it is read.
We read code more than we write it because we spend more time maintaining than we do writing from scratch. A line of code, once written, still has a long and storied life ahead of it. You write code once and then return to it multiple times, fixing bugs, adding features, refactoring. To do this you have to change the existing code—and to change it you have to read and understand it. Not just you; future programmers will also work on the code, pursuing their own goals, operating under different constraints.
“I don’t see the code any more.” (Image credit: Jahobr)
For every part of the code you need to revisit to in depth, there will be dozens of related parts you’re not touching directly. You need to navigate through the codebase to find relevant code and you need to track surrounding code for context. You don’t have to understand the related parts of code exactly; just what they are supposed to do. You do this not by reading the code in detail—nobody has the time or working memory to keep a whole codebase in their head!—but by scanning through code quickly and getting just the gist.
This is a multiplicative relationship. Just as you end up reading code multiple times for each time you write it, you end up skimming multiple times for each piece you read.
Writing code you can understand at a glance is at least as important as writing code that you can read at all.
I don’t like talking about “complexity” any more because while almost everyone agrees complexity is “bad”, people have radically different ideas of what “complexity” means.
“Complexity” in software conflates several distinct concepts:
plain poor design
complexity in operation rather than design (or technology)
inescapable real-world complexity
lots of moving pieces and details, code that strains working memory
abstract or novel concepts that are hard to learn up-front, but easy long-term
probably more I haven’t considered off-hand
Some of these notions are basically opposites! At the Pareto frontier of system design, there is a fundamental trade-off between having more abstract concepts that are harder to learn up-front and exposing more details that make systems hard to work with on an ongoing basis. But people dismiss both of these as “complexity”! These are two ideas that absolutely should not be conflated.
In my career, I’ve had the fortune to work with and observe a number of real experts in their fields. Expert programmers, statisticians, designers and leaders. Each person and each field were different, but there were broad similarities in how all the experts made decisions. The most effective teams I worked on not only included experts but also made room for them to work as experts.
But what does this actually entail?
Experts are not “beginners with more knowledge”; their expertise allows them to operate in a categorically different—and more effective!—manner. To work with experts effectively, we need a model of how they actually work.
Years ago, I heard a stupid philosophy joke: a student taking an intro philosophy class asks the professor “but how do we know?”; then, when the professor gives an answer, the student asks “okay, but how do we know that?” This keeps on going until eventually the professor gets fed up and says “by looking”.
I gather this is absolutely not how philosophers actually think about epistemology, but that final line has always stuck with me anyhow. I’ve repeatedly had suggestions to address issues at work—code quality is bad, our system design has fundamental issues, our management processes sap people’s autonomy and morale—met with the same refrain: “but how will we know?” How will we know that drawing better interface boundaries will improve our system design? How will we know that our codebase is better? How will we know that code quality or system design matters?
A useful mental tool for designing resilient software: consider how the system will operate in three separate regimes:
The happy path. Everything is handled automatically with no manual intervention needed.
Small issues crop up requiring narrowly scoped—but not necessarily routine—human intervention.
A large, unexpected issue crops up, affecting the entire system and requiring major, novel human intervention
I’m intentionally talking about “issues” rather than “incidents” because this framework applies to situations that do not parse as “software incidents”: think customer support issues, physical emergencies, regulatory audits or even emerging market opportunities. Quickly pivoting or expanding into a new area is not an incident, but it sure feels like a major issue to the folks working on it!
In hindsight, this would have been a useful tool for designing the inventory control system I worked on at Target, and it’s a tool I’m going to use for future systems I design.
A retail distribution center. (Photo credit: Nick Saltmarsh)
Fixing Haskell type errors can be hard. Learning how to understand and fix type errors was the first real obstacle I faced when I first picked up the language. I’ve seen the same tendency with every Haskell beginner I’ve taught.
With a bit of experience, I got so used to the quirks of GHC’s typechecker and Haskell’s standard library that I could resolve most type errors intuitively. Most but not all. Worse yet, the intuition that helped me in easier cases did not scale to harder errors; instead, fixing hard errors required frustrating trial-and-error. I did not have a mental toolkit for debugging confusing type errors.
An intimidating block of error messages for a single mistake!
At the same time, I was going through the same story with debugging in general. When I started programming all bugs were hard; gradually, I developed an intuition for fixing most bugs; but I did not have the mental tools to deal with hard bugs, leaving me thrashing around when my initial assumptions about a bug were wrong.
I was missing one key insight: you can debug systematically. Debugging is a skill you can learn—not just glorified guess-and-check. Realizing this, my approach to debugging improved significantly. I slowed down, stopped jumping in based on my initial assumptions and instead approached problems step-by-step, following some simple principles.
This insight translated to Haskell. We can fix Haskell type errors systematically. It’s a skill you can learn.
Let’s look at a simple framework for fixing type errors by following three principles:
Recently, I’ve revisited how I represent errors in code.
I’m working on a command-line tool used across multiple teams and I want to keep its error messages consistent and readable. As the codebase has grown, I’ve moved from ad hoc error strings throughout my code to a structured error type.
I never want to see this in my software!
Useful error messages need to:
Contain the information and context to diagnose and fix the problem.
Provide an intuitive explanation for new users.
Format information consistently, in a way that’s easy to scan at a glance.
We need 10–20 lines of code for each kind of error to generate error messages that fulfill these goals. In other projects, I would create error message strings directly in the code that first detected or raised an error, but that just does not scale here—it would add too much noise to my code! It’s much harder to keep error messages consistent in style when they are so decentralized, and refactoring messages en masse becomes a nightmare.
To fix these problems, I’ve started using dedicated types for my errors. This took some up-front effort but has more than paid for itself over time; I’ve found this approach has a number of advantages on top of improving error messages and I’m going to lean towards this style in all my future projects.
I believe the notion that Haskell uses “monads” to enforce purity is rather misleading. It has certainly caused quite a bit of confusion! It’s very much like saying we use “rings to do arithmetic”. We don’t! We use numbers, which just happen to form a ring with arithmetic operations. The important idea is the number, not the ring. You can—and most people do—do arithmetic without understanding or even knowing about rings. Moreover, plenty of rings don’t have anything to do with arithmetic.
Similarly, in Haskell, we use types to deal with effects. In particular, we use IO and State and ST, all of which happen to form monads. But it is still better to say we use “the IO type” to do IO or that we use State for state than to say we use “monads” to do IO or state.
Now, how does this work? Well, I’ll give you one view on the matter, using State as a case study.
Dynamic programming is a method for efficiently solving complex problems with overlapping subproblems, covered in any introductory algorithms course. It is usually presented in a staunchly imperative manner, explicitly reading from and modifying a mutable array—a method that doesn’t neatly translate to a functional language like Haskell.
Happily, laziness provides a very natural way to express dynamic programming algorithms. The end result still relies on mutation, but purely by the runtime system—it is entirely below our level of abstraction. It’s a great example of embracing and thinking with laziness.
So let’s look at how to do dynamic programming in Haskell and implement string edit distance, which is one of the most commonly taught dynamic programming algorithms. In a future post, I will also extend this algorithm to trees.
The differences between two strings, as computed by the edit distance algorithm.
A few years ago—back in high school—I spent a little while writing programs to automatically generate mazes. It was a fun exercise and helped me come to grips with recursion: the first time I implemented it (in Java), I couldn’t get the recursive version to work properly so ended up using a while loop with an explicit stack!
Making random mazes is actually a really good programming exercise: it’s relatively simple, produces cool pictures and does a good job of covering graph algorithms. It’s especially interesting for functional programming because it relies on graphs and randomness, two things generally viewed as tricky in a functional style.
So lets look at how to implement a maze generator in Haskell using inductive graphs for our graph traversal. Here’s what we’re aiming for:
 RSS
RSS 




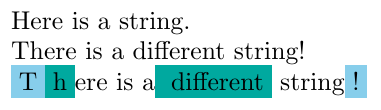


{kind=link}