blog | jelv.ishttp://jelv.is/blog/atom.xmlTikhon Jelvistikhon@jelv.is2020-12-13T00:31:29ZStructure your Errorshttp://jelv.is/blog/Structure-your-Errors2020-12-13 00:31:292020-12-13T00:31:29ZRecently, I’ve revisited how I represent errors in code.
I’m working on a command-line tool used across multiple teams and I want to keep its error messages consistent and readable. As the codebase has grown, I’ve moved from ad hoc error strings throughout my code to a structured error type.
I never want to see this in my software!
Useful error messages need to:
Contain the information and context to diagnose and fix the problem.
Provide an intuitive explanation for new users.
Format information consistently, in a way that’s easy to scan at a glance.
We need 10–20 lines of code for each kind of error to generate error messages that fulfill these goals. In other projects, I would create error message strings directly in the code that first detected or raised an error, but that just does not scale here—it would add too much noise to my code! It’s much harder to keep error messages consistent in style when they are so decentralized, and refactoring messages en masse becomes a nightmare.
To fix these problems, I’ve started using dedicated types for my errors. This took some up-front effort but has more than paid for itself over time; I’ve found this approach has a number of advantages on top of improving error messages and I’m going to lean towards this style in all my future projects.
What are structured errors?
When I talk about structured errors, I’m talking about how we represent the information attached to our errors rather than the control flow mechanism (like exceptions or monads) we use to handle them. When an error occurs, we assemble an object describing the error using actual values from the code—not just strings—giving us a structured representation of the error’s context. Extracting specific pieces of information from an error should not take any parsing or guesswork!
If a function could fail because an API it depends on returned an HTTP error code, a structured error from that function would be a project-specific ApiError value carrying several pieces of information:
Which API failed.
The HTTP code it failed with.
The HTTP request that resulted in the failed response.
The HTTP response itself.
Additional data needed to provide context, like which inputs to the function caused the failure.
Contrast this with some less structured alternatives:
We could bubble up the error from our HTTP library.
But this lacks context specific to our application, which makes debugging harder. If our code called the same API in multiple places, how would we know which call led to the error?
We could produce a string: "API Foo v2 failed with HTTP 400.".
But this is missing useful information—we need more details about exactly how the HTTP call failed—and the information it has is hard to extract.
How would we log or render the error in a different format? We would need to parse the details out of the string which would then break if we ever changed the text we’re using—text that is ostensibly meant for humans to read!
We could ignore the HTTP error and let the code fail somewhere down the line.
I’ve see in this in real projects! This is how a logical API error turns into undefined is not a function. The only upside with this style is that you feel like a hero once you find where the error was actually coming from.
These alternatives might be easier to use up-front, but leaves us less information and flexibility in the future. It’s a stock picture of technical debt: we’re making our life marginally easier today in return for harder debugging and refactoring tomorrow.
At heart, this is a question of code architecture. Structured errors separate the code that produces errors from the code that handles them.
When we encounter a condition in our code that produces error, we do not need to worry about what happens afterwards or how the error information will be used. Will it be logged? Will it be displayed to the user as text? Will it be displayed in a UI widget? Will it be caught and handled silently without alerting anyone? We don’t need answers to any of these questions; instead, we raise an error with all the context that we can and let downstream code handle it.
Error Messages
The reason I started exploring this approach was to produce detailed, readable and consistent error messages. The logic to render error messages for the user doesn’t have to fight for space and attention with domain-specific code; instead, it can be into a self-contained unit.
Here’s an example1 that would be overkill in the middle of normal code but works well when extracted to a function:
renderApiError ∷ApiError→TextrenderApiError e = [__i| API response from #{apiName e} (#{apiVersion e}) for customer #{customerId e} was missing required fields. Missing fields: #{bulletedList (missingFields e)} Raw response: #{encodeJson (apiResponse e)}|]
The API call that could produce this error is going to be a handful of lines at most, so having this sort of formatting code inline would overwhelm the code that actually does anything. Instead, we build a compact ApiError object at the call site and keep the extensive rendering code in some other part of the codebase. ApiError becomes an interface between the code that raises the error and the code for managing or displaying the error. Refactoring the domain code will not touch error rendering and vice-versa.
However, extracting rendering from the domain logic does not strictly need an error object. We could have a renderApiError function, use it at the API call site and raise an exception containing the resulting string. This physically separates error rendering and domain logic but still couples the two too tightly. How would we display the error in a UI? How would we keep statistics about API failures? What if we wanted to switch to a structured log format2? What if a future application has a way to recover from this error gracefully, depending on the details? Extracting the rendering logic into a function does not help for any of these situations. An ApiError object, on the other hand, could be caught and handled in arbitrary ways by upstream code without any downstream changes.
Like other sound architectural choices, clearly separating responsibilities—between producing and consuming errors—not only helps with our original goal of improving error messages but also makes our codebase simultaneously more flexible and easier to maintain.
For example, I have found structured errors help with debugging. I can include more information with the structured error object than I would provide in a human-readable string: dataframes that are too large to print, connections to active database sessions, closures… whatever makes sense and works with my resource management code. (Look out for leaks!) The first step of debugging is to observe the system, and a structured error gives me a lot of information quickly whether I’m using a debugger or adding a catch with print statements.
I did not consider debugging when I was first writing this code—I started thinking about errors in terms of error messages, and then I focused on how responsibilities should logically be split in my code. Everything else flows from that.
Errors that are exposed outside of your own code become part of your public API, and keeping the errors structured makes the API more discoverable and flexible. When I started thinking in these terms, I also started testing errors—does calling my code in intentionally incorrect ways raise the error I expect? Turns out that writing tests is also easier with a structured error object than with a string, since I can assert exactly the equalities I need without parsing strings or coupling my tests to user-facing error messages.
All these advantages stem from a heuristic I’ve found useful for system design in general: try to keep data structured as long as possible and push operations that lose information towards the edges of your system. Information is fundamentally easier to destroy than to (re)create!
Structuring Errors in Haskell
So far, everything I’ve talked about is language-agnostic. Structured errors make as much sense in Python as they do in Haskell. The implementation details, however, vary wildly between language and Haskell has some unique considerations.
So: how do we structure errors in Haskell? Or, at least, how did I structure my errors in Haskell?
An Error Type
The first step, in classical Haskell style, is to define a type.
Let’s say we’re implementing a small configuration language. What kind of errors might we encounter? Here are a few examples:
Parse errors, if a config file has invalid syntax.
File I/O errors if a file doesn’t exist or we don’t have permissions to read it.
Missing fields, if a file doesn’t specify mandatory fields.
Unknown fields, if a file has unexpected fields.
As you implement the tool you’ll probably find other kinds of errors, but this is a solid starting point. We can turn this list directly into an algebraic data type:
Each of the constructors of Error captures the context for one kind of error, giving you enough information to handle the problem. Any functions you write that might cause errors would signal using Error3:
parseConfig ∷MonadErrorError m ⇒FilePath→Text→ m ConfigparseConfig source body =case Parsec.parse config source body ofLeft parseError → throwError (ParseError parseError)Right parsed →pure parsed
If our input doesn’t parse, we wrap the error Parsec gives us—a structured object itself—into our Error type. The errors Parsec provides are thorough so we don’t need anything else, but if we did, we could add more fields to the ParseError constructor.
Next, we need a way to handle our errors. We’re writing a command-line tool, so let’s render the error as user-friendly text:
As long as you enable -Wincomplete-patterns—which should really be on by default—the compiler will remind you to update renderError whenever you add new kinds of errors.
In the future, we could also add other rendering functions:
A simple Error type is a solid strategy for structuring errors in smaller Haskell programs and libraries but does not scale well to larger codebases.
A global, centralized error type is inherently anti-modular: Error has to know about every single kind of error in your whole codebase. Any time you write code that can fail in new ways, you have to update the Error module as well. We also start running into circular dependency issues: the Error type needs to have a field with a type defined in module Foo, but Foo wants to import Error for handling its own errors! Haskell does not support mutually recursive modules4, and I’ve found that wanting them is usually a sign that my overall design is not factored well.
So how can we make our Error type extensible?
The cleanest solution would be some kind of structural subtyping similar to OCaml’s polymorphic variants5. Unfortunately, we do not have anything like this built into Haskell, and my experience with libraries implementing extensible types has been uniformly poor6.
So the first thing I tried—the first thing I try whenever I need to make a Haskell type more flexible—was adding a type parameter:
dataError a =ParseErrorParsec.ParseError|IOErrorIOException|MissingFieldFilePathFieldName|UnknownFieldFilePathFieldName|OtherError a
The idea is that a would stand for module-specific error types. General functions like parseConfig would be polymorphic in a:
parseConfig ∷MonadError (Error a) m ⇒FilePath→Text→ m ConfigparseConfig =...
Functions in new modules with their own kinds of errors would specify their error type for a. For example, if we added support for reading config values from Avro records, we would write something like:
avroConfig ∷MonadError (ErrorAvroError) m⇒FilePath→Avro.Value→ m ConfigavroConfig =...
AvroError would play the role of Error for the AvroConfig module specifically.
But how would this extend to multiple modules with their own error type? Would I have to add a parameter to each type (ie AvroError a) and chain them together like a type-level list? That sounds tedious and error-prone! Besides, what do we gain from specifying each error type in the type variable?
Existential Types
Using a type variable did not seem like a fruitful design direction. Instead, I decided to make the “other error” variable existential7:
dataError=ParseErrorParsec.ParseError|...|OtherErrorSomeErrordataSomeErrorwhereSomeError∷ e →SomeError
SomeError lets me wrap a value of any type into an Error without needing to manage any visible type variables. Going back to my Avro example, if I have an error e ∷ AvroError, I can turn that into an Error value with OtherError (SomeError e). Functions in the AvroConfig module can now have types compatible with the rest of our codebase:
avroConfig ∷MonadErrorError m ⇒FilePath→Avro.Value→ m ConfigavroConfig =...
In practice, I found it was also useful to include a human-readable tag telling me which module a specific error type came from:
This led to a simple pattern for adding new modules: each module defines a dedicated error type as well as a function to throw errors of that type wrapped into the base Error type:
throw ∷MonadErrorError m ⇒AvroError→ m athrow avroError = MonadError.throwError (OtherError"Avro" (SomeError avroError))
Using Existential Errors
Now that I have a way to throw errors of different types, what can I do with them?
With the code I’ve shown so far? Nothing.
The problem is that SomeError, as written, takes values of any type with no way to know what type it contains! That is fundamental to how existential types work, but it means I need to place some restrictions on SomeError to make it useful.
For every operation I want to perform on errors—rendering to the user, debugging in the interpreter, logging—I need to know that whatever type is hidden inside SomeError supports that operation. In Haskell, the best option is to add typeclass constraints to SomeError; for example, if I needed to return errors as JSON, I could constrain SomeError to only accept arguments of type e if the type were an instance of Aeson.ToJSON:
dataSomeErrorwhereSomeError∷ (Aeson.ToJSON e) ⇒ e →SomeError
Think about it this way: every function in our original, non-modular design now needs to handle multiple types in an extensible way. Otherwise, how would we deal with error types defined in future modules? Typeclasses are the mechanism Haskell provides to extend a function over an open-ended set of types.
classRenderError e where renderError ∷ e →TextinstanceRenderErrorErrorwhere renderError = \caseParseError parseError → [__i| Failed to parse #{sourceName (sourcePos parseError)}: #{show parseError } |]...OtherError moduleName error→ [__i| #{show moduleName} error: #{renderError error} |]
A typeclass is more complex than a plain function but that is the price we pay for extensibility.
As a bonus, we can define instances for other types; this not only avoids code duplication but also helps keep the format of our error messages consistent across the entire codebase. This is not substantially different from writing distinct functions for each type (renderCustomerId, renderAvro… etc), but it better-reflects the conceptual organization of the code and saves us from juggling lots of type-specific function names.
Each capability errors should have requires a typeclass. In some cases we define the classes just for error handling; in other cases, we can just reuse existing classes. Here are a few more examples, aside from rendering as text or JSON:
Show for GHCi and debugging
LogFormat if we’re using structured logging
ToElement if we’re displaying errors in an HTML UI
whatever else you need to process errors
Typeclasses give us a modular way to consume multiple types of errors in multiple ways. Both adding new types of errors and adding new capabilities is reasonably easy. When we add a new error type, the compiler tells us what instances we need to implement to use SomeError; when we add a new typeclass, adding that constraint to SomeError will point us to all the existing types that need new instances.
Catching Existential Errors
The last part of the puzzle came up when I went to write tests for my new exceptions.
Let’s say I have a function in the AvroConfig module that I expect to raise a specific AvroError. How do I write a unit test to check this?
I could catch the error, pattern match on OtherError and convert the underlying error object to JSON, but this is deeply unsatisfying. The point of using structured errors was that I could use them as normal Haskell values for things like testing; converting to JSON defeats the whole purpose.
To solve this, I borrowed a trick from Haskell’s own exception system in Control.Exception8. Our goal is to have a function that tries to extract a specific type of error from SomeError; if the SomeError is carrying a value of the right type we get Just that value and otherwise we get Nothing:
fromError ∷Error→Maybe e
Note how the type variable e only exists in the return value of fromError (just like read or fromInteger). This isn’t a problem if we can infer a concrete type, but if e is ambiguous we might need to specify the type explicitly using TypeApplications:
fromError @AvroError err
This function now gives us a way to check—at runtime—whether the error hidden inside SomeError has a specific type, and, if it does, extract that value. This is all we need to write tests.
To implement fromError, we’re going to rely on a bit of Typeable magic—a capability added to GHC for just this sort of use:
classTypeable e ⇒CatchableError e where fromError ∷Error→Maybe e fromError (OtherError _ (SomeError e)) = Typeable.cast e fromError _ =Nothing
Since we have a default implementation for the only method in this class, writing instances is as simple as:
data AvroError = ...
instance CatchableError AvroError
Finally, we need to add this class to the SomeError type.
Since CatchableError is pretty generic, it is also convenient to move every other constraint from SomeError—Show, RenderError, ToJSON… etc—to be a superclass of CatchableError. This is purely a stylistic choice and you could accomplish exactly the same effect with a type synonym instead.
These changes give us the following definition of SomeError:
dataSomeErrorwhereSomeError∷ (CatchableError e) ⇒ e →SomeError
With all the CatchableError machinery in place, we can write tests for specific types of errors:
testCase "check specific error"$$docase failingOperation ofLeft err →case fromError @ModuleError err ofJust got → assert (got == expected)Nothing→fail"Wrong type of error!"Right res →fail"Expected error but got: "<>show res
We don’t have to use this just for testing. The fromError mechanism lets us catch and handle errors however we like, which lets us write code that catches, inspects and even recovers from domain-specific errors.
An Error Pattern
With all these pieces in place, we have a pattern for structured extensible errors in Haskell:
Start by defining an Error type for your core code.
When you need modularity, add an existentially typed SomeError type.
In new modules, define module-specific Error types and throw functions.
Add typeclasses for each operation you want to perform on your structured errors.
Define a CatchableError class using Typeable so that you can extract errors of specific types at runtime.
I could imagine variations on this design: for example, we could make SomeError our central error type and not have any other constructors in Error at all. We could also start building more complex hierarchies of errors. This is not meant to be a prescriptive guide to error handling in Haskell; it’s a reflection of how my code in particular evolved over time, and the core ideas that helped it work relatively well.
I did not start my project with this pattern in mind. A single centralized Error type served me perfectly well for a long time, and the other details evolved through a number of iterations. Getting all the pieces into place required some setup and complexity and I’m not sure this is the “best” design for extensible errors, but I’ve had a great experience using this pattern so far and will use a similar pattern on future projects.
I can’t share an example from my real code at the moment, but this captures the same idea. The quasiquoter comes from the string-interpolate package.↩︎
Structured logging has similar benefits to structured errors. I didn’t want to go into too much detail about it—this blog post was getting too long as-is—but it could be a fun topic for a future post.↩︎
I used MonadError in this example because that’s what I use in my own code, but this works just as well with any other error mechanism including plain old Either Error a.↩︎
Technically, GHC does support mutually recurisve modules with .hs-boot files, but this is an awkward feature that I would never use in my code—it exists to solve a small number of otherwise unavoidable problems, mostly in GHC’s own standard library.↩︎
Polymorphic variants are probably the single feature I miss the most in Haskell compared to OCaml. Extensible records and sum types—coupled with some kind of row polymorphism—are the number one feature I want added to Haskell, but I understand that both the design and implementation of row polymorphism in Haskell are substantially more difficult than they seem.
I should note that I have not used extensible type libraries extensively, but I’ve evaluated a few in the past. In my experience, these libraries:
are far more awkward to use than “normal” algebraic data types
have complex type-level implementations that leak into their APIs and error messages
have inconsistent and generally poor performance
While Haskell is theoretically expressive enough to provide extensible types as a library, I believe it is not possible to make them efficient or ergonomic without language-level support.↩︎
Both my code and Mark’s post use the GADTSyntax extension for writing existential types. In older code and documentation, you might run into the older existential type syntax instead:
dataSomeError=forall e.SomeError e
While this is strictly a matter of style—both declarations define the same type—I believe the GADT-style syntax is so much clearer (and more flexible to boot) that the other syntax should be considered obsolete.↩︎
]]>
Haskell, Monads and Purityhttp://jelv.is/blog/Haskell-Monads-and-Purity2014-10-01 20:15:442014-10-01T20:15:44ZI believe the notion that Haskell uses “monads” to enforce purity is rather misleading. It has certainly caused quite a bit of confusion! It’s very much like saying we use “rings to do arithmetic”. We don’t! We use numbers, which just happen to form a ring with arithmetic operations. The important idea is the number, not the ring. You can—and most people do—do arithmetic without understanding or even knowing about rings. Moreover, plenty of rings don’t have anything to do with arithmetic.
Similarly, in Haskell, we use types to deal with effects. In particular, we use IO and State and ST, all of which happen to form monads. But it is still better to say we use “the IO type” to do IO or that we use State for state than to say we use “monads” to do IO or state.
Now, how does this work? Well, I’ll give you one view on the matter, using State as a case study.
State
Perhaps the most important philosophical idea is that Haskell does not “enforce” purity. Rather, Haskell as a language simply does not include any notion of effects. Base Haskell is exclusively about evaluation: going from an expression like 1 + 2 to 3. This has no provisions for side effects; they simply don’t make any sense in this context1.
Side effects and mutation are not prohibited; they simply weren’t added in the first place. But let’s say that, on a flight of fancy, you decide you really want some mutable state in your otherwise-happy Haskell code. How can you do this? Here’s one option: implement the state machinery yourself. You can do this by creating a little sub-language and writing an interpreter for it. The language itself is actually just a data type; the interpreter is just a normal function which takes care of evaluating your stateful sub-program and maintaining the state.
Let’s call our sub-language’s type State. A single State “action” has some value as the result, so it needs a type parameter: State a. For the sake of simplicity, let’s imagine you only ever want a single piece of state—an Int. (You could easily generalize this to any type of state, say a variable s, or, with a bit more effort, a state type that could change over time. But we’ll consider the simplest case.)
So what sorts of actions do we need to support? One thing we want to do is ignore the current state: if we have an a already, we want to have a State a which just evaluate to that. It’s a way to add constants to our sub-language.
We also want some way to get and set the state. Getting should just evaluate to the current value of the state; setting should take the new value to set. Since setting does not have a meaningful return value, we can just return (). Three basic actions: return some value, get the state and set the state:
return ∷ a → State a
get ∷ State Int
set ∷ Int → State ()
However, these actions by themselves are rather boring. We need some way to string them together—some way to compose actions. The simplest way is to just sequence two actions: run one, get the new state and run the next one. We can call this an infix >>:
(>>) ∷ State a → State b → State b
When our interpreter sees a composed action like this, it will just evaluate the left one, get the resulting state and evaluate the second one using this new state. For example, set 10 >> get will result in 10. However, this is still missing something. We can’t really use the value of the state in interesting ways. In fact, we can’t even write a simple program to increment the state value! We need some way to use arbitrary Haskell logic inside of our stateful programs.
How do we do this? Well, since we want to use arbitrary logic, we’re looking to support some sort of user-supplied function embedded into our language. Since Haskell only knows how to work with a values rather than State a values, this function should take a a. Since we want to use this logic to set the state, this function should return a state action. The type we want looks something like this:
a → State b
This function has an interesting “shape” (for lack of a better word). By going from a normal value (a) to a state action (State b), we’re injecting normal Haskell into our state sub-language. Since we’re also transitioning from a to b, we’re enabling arbitrary logic in the function. We can now use this to write an incrementing function:
addToState ∷ Int → State ()
addToState x = set (x + 1)
Now, how do we intersperse this sort of function with our normal state actions? Well, we want to take a state action, one of these functions, combine them and get the result. The type we want, then, is:
State a → (a → State b) → State b
Quite similar to our existing >> function; the only difference is that the second “action” is a function now. When our interpreter sees this, it will evaluate the lefthand side, plug the result into the righthand function, get the new state action and run it with the updated state.
With this, we can combine get and addToState giving us a program that increments our current state by 1. We can use this approach to execute arbitrary logic using our state. We can call this sort of composition >>=, a fancier version of >>:
(>>=) ∷ State a → (a → State b) → State b
Using this >>= operator, we can write the increment program:
increment = get >>= addToState
and if we want to increment three times in a row, we can do this:
increment3 = increment >> increment >> increment
It’s important to note that the >>= doesn’t do anything; it just produces some data structure which contains both the lefthand side and the function. It’s our interpreter function that will ever do anything. increment is just a normal value of the type State (); nothing special. This means that the order in which our expressions get evaluated does not affect how our state works—we’re just evaluating an AST; the state effects are all managed by the interpreter function. This neatly separates our stateful, observable execution from Haskell’s evaluation order which is below our level of abstraction and therefore not observable.
Now whenever we want to use some mutable state, we just write our program using this State a type, combining the disparate parts using >>=. Then, to actually use this, we invoke our interpreter function. This function looks at the State a value and evaluates it, threading the changing state through each part. The exact details of how the interpreter works, or even how a State a value is represented internally, are not particularly important.
Unfortunately, using >>= and >> gets rather ugly, so we also want to throw in some syntax sugar to make using this type look like a reasonable imperative program. This will make our little sub-language bearable and the resulting code easier to read. We can o this with two core patterns: action₁ >> action₂ will get transformed into two lines of code:
do action₁
action₂
and action₁ >>= \ x → action₂ will be transformed into
do x ← action₁
action₂
Now our sequences of actions actually look like sequences of statements in a normal language.
We’ve added state to a language where it normally simply does not exist. All using normal functions and data types, with just a bit of syntax sugar to help the medicine go down. Nifty. But not really magical.
By now, you’ve probably realized that return and >>= make State a monad. The syntax sugar, of course, is do-notation. But if you’re interested in how we get mutable state, this doesn’t tell you very much. Instead, the relevant bits are what the State a type looks like (it’s basically an AST of commands) and what the interpreter does. The fact that it’s a monad is useful, but does not entirely characterize the State type.
IO
Sure, we can add state by producing a little AST and explicitly evaluating it. But it’s easy to model state because it’s an entirely internal phenomenon to the program. But how do we deal with external effects—IO? This is something we fundamentally can’t express with normal Haskell types and functions.
The basic idea is the same: we assemble a program and run it through an interpreter which manages the effects. The main difference is that this interpreter itself is not written in Haskell—it has to be built in. This interpreter is actually the Haskell runtime system and, by extension, the whole operating system.
So, in some sense, IOis magical, but this is inevitable: to produce the actual effects, it has to talk to the operating system and ultimately the hardware directly. You simply can’t do this within normal Haskell because Haskell only knows about evaluating expressions. Talking to the OS is generally below our level of abstraction. And ultimately, this requires magic because it is magic—it’s built right into the hardware!
So the runtime system is our interpreter for IO. A Haskell program has a main value which is an IO action; when you run this program, what you’re actually doing is evaluating main and then giving it to the runtime system to interpret. This system then runs the effects, intoning the appropriate incantations to make things happen in the real world.
The IO type is just something the compiler and runtime system understand and run. It is a monad in basically the same way as our State type above. Conceptually, the only difference is in how it gets interpreted.
In reality, of course, things aren’t implemented like this. But it’s a reasonable way of thinking about it.
So the final verdict: Haskell does not “use monads to manage effects”. Rather, Haskell has types like IO to manage effects, and IO happens to form a monad. Moreover, it turns out that the monad operations are very useful to write actual programs by composing IO actions.
Why
After reading all this, a reasonable question is simply “why?”. Why bother with all this? Why separate effects out and build all this conceptual machinery to achieve them again?
There are a few answers to this, but all ultimately boil down to raising our level of abstraction and making our language more expressive.
This system separates evaluation and execution: calculating a value and performing an action are now different. Haskell does not have a hard notion of “now” strung throughout the code, because the order of evaluation does not have visible effects2. We’re no longer constrained in writing our definitions in the order they need to be evaluated; instead, we’re free to organize our code, even at a very local level, based on how we want it to be read. This extra notion of “now” and an environment that changes over time (ie mutable state) is not necessary in most code; getting rid of it limits cognitive load.
In essence, we move evaluation below our level of abstraction. Instead of being an omnipresent facet of every line we write, evaluation now happens largely in the background. Is it always a perfect abstraction? No. We have performance concerns which can sometimes be dire and we have ways to completely break the abstraction (unsafePerformIO and friends). But does it have to be perfect to be useful?
It doesn’t. Think of it like garbage collection: GC moved allocating and deallocating memory below our level of abstraction and pushed programming languages ahead. At the same time, it has similar pitfalls to non-strictness: performance concerns and similar ways to break the abstraction (unsafe blocks, FFI, low-level apis into the GC). And yet it’s incredibly useful, a net win in a majority of applications.
To me, at least, this separation is also very useful at a more semantic level: it helps me think about code. I hold actions and calculations mentally distinct and Haskell adroitly reflects this distinction. I tend to organize my code along these lines even in other languages that do not distinguish between the two directly.
Our pure code lives in an idyllic world free from hidden dependencies and complexity, and we can still splash in a dash of state—or any other sort of effect—at will.
Moreover, these effects we splash in are now first-class citizens. You can write functions that depend on having access to a particular effect or ones that are polymorphic over their capabilities. You have fine control over exactly what the “effect” is: you could have just state or variables or IO or a restricted subset of IO or…
This fine control over effects isn’t useful just for making your code more maintainable: it also gives us new capabilities. The “halo” application is concurrency and parallelism, where Haskell libraries really shine. For concurrency, things like STM would be tricky, at best, without tight controls over IO; for parallelism, the same is true of Haskell’s strategies which parallelize code deterministically—they’re guaranteed not to change the semantics, just the running time.
This is why unsafePerformIO is unsafe: it’s completely foreign to the programming model.↩︎
It can, however, still cause visible performance issues, which is why performance optimization is often cited as one of the hardest aspects of practical Haskell.↩︎
]]>
Lazy Dynamic Programminghttp://jelv.is/blog/Lazy-Dynamic-Programming2014-05-25 15:29:332014-05-25T15:29:33ZDynamic programming is a method for efficiently solving complex problems with overlapping subproblems, covered in any introductory algorithms course. It is usually presented in a staunchly imperative manner, explicitly reading from and modifying a mutable array—a method that doesn’t neatly translate to a functional language like Haskell.
Happily, laziness provides a very natural way to express dynamic programming algorithms. The end result still relies on mutation, but purely by the runtime system—it is entirely below our level of abstraction. It’s a great example of embracing and thinking with laziness.
So let’s look at how to do dynamic programming in Haskell and implement string edit distance, which is one of the most commonly taught dynamic programming algorithms. In a future post, I will also extend this algorithm to trees.
The differences between two strings, as computed by the edit distance algorithm.
This post was largely spurred on by working with Joe Nelson as part of his “open source pilgrimage”. We worked on my semantic version control project which, as one of its passes, needs to compute a diff between parse trees with an algorithm deeply related to string edit distance as presented here. Pairing with Joe really helped me work out several of the key ideas in this post, which had me stuck a few years ago.
Dynamic Programming and Memoization
Dynamic programming is one of the core techniques for writing efficient algorithms. The idea is to break a problem into smaller subproblems and then save the result of each subproblem so that it is only calculated once. Dynamic programming involves two parts: restating the problem in terms of overlapping subproblems and memoizing.
Overlapping subproblems are subproblems that depend on each other. This is where dynamic programming is needed: if we use the result of each subproblem many times, we can save time by caching each intermediate result, only calculating it once. Caching the result of a function like this is called memoization.
Memoization in general is a rich topic in Haskell. There are some very interesting approaches for memoizing functions over different sorts of inputs like Conal Elliott’s elegant memoization or Luke Palmer’s memo combinators.
The general idea is to take advantage of laziness and create a large data structure like a list or a tree that stores all of the function’s results. This data structure is defined circularly: recursive calls are replaced with references to parts of the data structure. Thanks to laziness, pieces of the data structure only get evaluated as needed and at most once—memoization emerges naturally from the evaluation rules. A very illustrative (but slightly cliche) example is the memoized version of the Fibonacci function:
The fib function indexes into fibs, an infinite list of Fibonacci numbers. fibs is defined in terms of itself : instead of recursively calling fib, we make later elements of fibs depend on earlier ones by passing fibs and (drop 1 fibs) into zipWith (+). It helps to visualize this list as more and more elements get evaluated:
zipWith f applies f to the first elements of both lists then recurses on their tails. In this case, the two lists are actually just pointers into the same list!
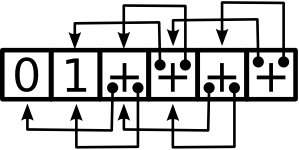
Note how we only ever need the last two elements of the list. Since we don’t have any other references to the fibs list, GHC’s garbage collector can reclaim unused list elements as soon as we’re done with them. So with GC, the actual execution looks more like this:
More memory efficient: we only ever store a constant number of past results.
Lazy Arrays
Dynamic programming algorithms tend to have a very specific memoization style—sub-problems are put into an array and the inputs to the algorithm are transformed into array indices. These algorithms are often presented in a distinctly imperative fashion: you initialize a large array with some empty value and then manually update it as you go along. You have to do some explicit bookkeeping at each step to save your result and there is nothing preventing you from accidentally reading in part of the array you haven’t set yet.
This imperative-style updating is awkward to represent in Haskell. We could do it by either passing around an immutable array as an argument or using a mutable array internally, but both of these options are unpleasant to use and the former is not very efficient.
Instead of replicating the imperative approach directly, we’re going to take advantage of Haskell’s laziness to define an array that depends on itself. The trick is to have every recursive call in the function index into the array and each array cell call back into the function. This way, the logic of calculating each value once and then caching it is handled behind the scenes by Haskell’s runtime system. We compute the subproblems at most once in the order that we need and the array is always used as if it was fully filled out: we can never accidentally forget to save a result or access the array before that result has been calculated.
At its heart, this is the same idea as having a fibs list that depends on itself, just with an array instead of a list. Arrays fit many dynamic programming problems better than lists or other data structures.
We can rewrite our fib function to use this style of memoization. Note that this approach is actually strictly worse for Fibonacci numbers; this is just an illustration of how it works.
fib' max= go maxwhere go 0=0 go 1=1 go n = fibs ! (n -1) + fibs ! (n -2) fibs = Array.listArray (0, max) [go x | x <- [0..max]]
The actual recursion is done by a helper function: we need this so that our memoization array (fibs) is only defined once in a call to fib' rather than redefined at each recursive call!
For calculating fib' 5, fibs would be an array of 6 thunks each containing a call to go. The final result is the thunk with go 5, which depends on go 4 and go 3; go 4 depends on go 3 and go 2 and so on until we get to the entries for go 1 and go 0 which are the base cases 1 and 0.
The array of sub-problems for fib 5.
The nice thing is that this tangle of pointers and dependencies is all taken care of by laziness. We can’t really mess it up or access the array incorrectly because those details are below our level of abstraction. Initializing, updating and reading the array is all a result of forcing the thunks in the cells, not something we implemented directly in Haskell.
String Edit Distance
Now that we have a neat technique for dynamic programming with lazy arrays, let’s apply it to a real problem: string edit distance. This is one of the most common examples used to introduce dynamic programming in algorithms classes and a good first step towards implementing tree edit distance.
The edit distance between two strings is a measure of how different the strings are: it’s the number of steps needed to go from one to the other where each step can either add, remove or modify a single character. The actual sequence of steps needed is called an edit script. For example:
"brother" → "bother" remove 'r'
"bother" → "brother" add 'r'
"sitting" → "fitting" modify 's' to 'f'
The distance between strings \(a\) and \(b\) is always the same as the distance between \(b\) and \(a\). We go between the two edit scripts by inverting the actions: flipping modified characters and interchanging adds and removes.
The Wagner-Fischer algorithm is the basic approach for computing the edit distance between two strings. It goes through the two strings character by character, trying all three possible actions (adding, removing or modifying) and picking the action that minimizes the distance.
For example, to get the distance between "kitten" and "sitting", we would start with the first two characters k and s. As these are different, we need to try the three possible edit actions and find the smallest distance. So we would compute the distances between "itten" and "sitting" for a delete, "kitten" and "itting" for an insert and "itten" and "itting" for a modify, and choose the smallest result.
This is where the branching factor and overlapping subproblems come from—each time the strings differ, we have to solve three recursive subproblems to see which action is optimal at the given step, and most of these results need to be used more than once.
We can express this as a recurrence relation. Given two strings \(a\) and \(b\), \(d_{ij}\) is the distance between their suffixes of length \(i\) and \(j\) respectively. So, for "kitten" and "sitting", \(d_{6,7}\) would be the whole distance while \(d_{5,6}\) would be between "itten" and "itting".
The base cases \(d_{i0}\) and \(d_{0j}\) arise when we’ve gone through all of the characters in one of the strings, since the distance is just based on the characters remaining in the other string. The recursive case has us try the three possible actions, compute the distance for the three results and return the best one.
We can transcribe this almost directly to Haskell:
naive a b = d (length a) (length b)where d i 0= i d 0 j = j d i j| a !! (i -1) == b !! (j -1) = d (i -1) (j -1)|otherwise=minimum [ d (i -1) j +1 , d i (j -1) +1 , d (i -1) (j -1) +1 ]
And, for small examples, this code actually works! You can try it on "kitten" and "sitting" to get 3. Of course, it runs in exponential time, which makes it freeze on larger inputs—even just "aaaaaaaaaa" and "bbbbbbbbbb" take a while! The practical version of this algorithm needs dynamic programming, storing each value \(d_{ij}\) in a two-dimensional array so that we only calculate it once.
We can do this transformation in much the same way we used the fibs array: we define ds as an array with a bunch of calls to d i j and we replace our recursive calls d i j with indexing into the array ds ! (i, j).
basic a b = d m nwhere (m, n) = (length a, length b) d i 0= i d 0 j = j d i j| a !! (i -1) == b !! (j -1) = ds ! (i -1, j -1)|otherwise=minimum [ ds ! (i -1, j) +1 , ds ! (i, j -1) +1 , ds ! (i -1, j -1) +1 ] ds = Array.listArray bounds [d i j | (i, j) <- Array.range bounds] bounds = ((0, 0), (m, n))
This code is really not that different from the naive version, but far faster.
Faster Indexing
One thing that immediately jumps out from the above code is !!, indexing into lists. Lists are not a good data structure for random access! !! is often a bit of a code smell. And, indeed, using lists causes problems when working with longer strings.
We can solve this by converting a and b into arrays and then indexing only into those. (We can also make the arrays 1-indexed, simplifying the arithmetic a bit.)
better a b = d m nwhere (m, n) = (length a, length b) a' = Array.listArray (1, m) a b' = Array.listArray (1, n) b d i 0= i d 0 j = j d i j| a' ! i == b' ! j = ds ! (i -1, j -1)|otherwise=minimum [ ds ! (i -1, j) +1 , ds ! (i, j -1) +1 , ds ! (i -1, j -1) +1 ] ds = Array.listArray bounds [d i j | (i, j) <- Array.range bounds] bounds = ((0, 0), (m, n))
The only difference here is defining a' and b' and then using ! instead of !!. In practice, this is much faster than the basic version.
Note: I had a section here about using lists as loops which wasn’t entirely accurate or applicable to this example, so I’ve removed it.
Final Touches
Now we’re going to do a few more changes to make our algorithm complete. In particular, we’re going to calculate the edit script—the list of actions to go from one string to the other—along with the distance. We’re also going to generalize our algorithm to support different cost functions which specify how much each possible action is worth.
The first step, as ever, is to come up with our data types. How do we want to represent edit scripts? Well, we have four possible actions:
dataAction=None|Add|Remove|Modify
We’ll also take an extra argument, the cost function, which makes our final function type:
We could calculate the action by traversing our memoized array, seeing which action we took at each optimal step. However, for simplicity—at the expense of some performance—I’m just going to put the script so far at each cell of the array. Thanks to laziness, only the scripts needed for the end will be evaluated… but that performance gain is more than offset by having to store the extra thunk in our array.
The basic skeleton is still the same. However, we need an extra base case: d 0 0 is now special because it’s the only time we have an empty edit script. We extract the logic of managing the edit scripts into a helper function called go. At each array cell, I’m storing the score and the list of actions so far: (Distance, [Action]). Since the script is build up backwards, I have to reverse it at the very end.
script cost a b =reverse.snd$$ d m nwhere (m, n) = (length a, length b) a' = Array.listArray (1, m) a b' = Array.listArray (1, n) b d 00= (0, []) d i 0= go (i -1) 0Remove d 0 j = go 0 (j -1) Add d i j| a' ! i == b' ! j = go (i -1) (j -1) None|otherwise= minimum' [ go (i -1) j Remove , go i (j -1) Add , go (i -1) (j -1) Modify ] minimum' = minimumBy (comparing fst) go i j action =let (score, actions) = ds ! (i, j) in (score + cost action, action : actions) ds = Array.listArray bounds [d i j | (i, j) <- Array.range bounds] bounds = ((0, 0), (m, n))
The final piece is explicitly defining the old cost function we were using:
cost ::Action->Distancecost None=0cost _ =1
You could also experiment with other cost functions to see how the results change.
We now have a very general technique for writing dynamic programming problems. We take our recursive algorithm and:
add an array at the same scope level as the recursive function
define each array element as a call back into the function with the appropriate index
replace each recursive call with an index into the array
This then maintains all the needed data in memory, forcing thunks as appropriate. All of the dependencies between array elements—as well as the actual mutation—is handled by laziness. And, in the end, we get code that really isn’t that far off from a non-dynamic recursive version of the function!
For a bit of practice, try to implement a few other simple dynamic programming algorithms in Haskell like the longest common substring algorithm or CYK parsing.
]]>
Generating Mazes with Inductive Graphshttp://jelv.is/blog/Generating-Mazes-with-Inductive-Graphs2014-04-09 16:45:112014-04-09T16:45:11ZA few years ago—back in high school—I spent a little while writing programs to automatically generate mazes. It was a fun exercise and helped me come to grips with recursion: the first time I implemented it (in Java), I couldn’t get the recursive version to work properly so ended up using a while loop with an explicit stack!
Making random mazes is actually a really good programming exercise: it’s relatively simple, produces cool pictures and does a good job of covering graph algorithms. It’s especially interesting for functional programming because it relies on graphs and randomness, two things generally viewed as tricky in a functional style.
So lets look at how to implement a maze generator in Haskell using inductive graphs for our graph traversal. Here’s what we’re aiming for:
A simple maze built from a grid.
Inductive graphs are provided by Haskell’s “Functional Graph Library” fgl.
All of the code associated with this post is up on GitHub so you can load it into GHCi and follow along. It’s also a good starting point if you want to hack together your own mazes later on. It’s all under a BSD3 license, so you can use it however you like.
The Algorithm
We can generate a perfect maze by starting with a graph representing a grid and generating a random spanning tree. A perfect maze has exactly one path between any two points—no cycles or walled-off areas. A spanning tree of a graph is a tree that connects every single node in the graph.
There are multiple algorithms we can use to generate such a tree. Let’s focus on the simplest one which is just a randomized depth first search (DFS):
start with a grid that has every possible wall filled in
choose a cell to begin
from your current cell, choose a random neighbor that you haven’t visited yet
move to the chosen neighbor, knocking down the wall between it
if there are no unvisited neighbors, backtrack to the previous cell you were in and repeat
otherwise, repeat from your new cell
Our algorithm starts with a grid and produces a maze by deleting walls.
Inductive Data Types
To write our DFS, we need some way to represent a graph. Unfortunately, graphs are often inconvenient functional languages: standard representations like adjacency matrices or adjacency lists were designed with an imperative mindset. While you can certainly use them in Haskell, the resulting code would be relatively awkward.
But what sorts of structures does Haskell handle really well? Trees and lists come to mind: we can write very natural code by pattern matching. A very common pattern is to inspect a list as a head element and a tail, recursing on the tail:
foo (x:xs) = bar x : foo xs
Exactly the same pattern is useful for trees where we recurse on the children of a node:
foo (Node x children) =Node (bar x) (map foo children)
This pattern of choosing a “first” element and then recursing on the “rest” of the structure is extremely powerful. I like to think of it as “layering” your computation on the “shape” of the data structure.
We can decompose lists and trees like this very naturally because that’s exactly how they’re constructed in the first place: pattern matching is just the inverse of using the constructor normally. Even the syntax is the same! The pattern (x:xs) decomposes the result of the expression (x:xs). And since we’re just following the inherent structure of the type, there is always exactly one way to break the type apart.
These sorts of types are called inductive data types by analogy to mathematical induction. Generally, they have two branches: a base case and a recursive case—just like a proof by induction! Consider a List type:
dataList a =Empty-- base case|Cons a (List a) -- inductive case
Pretty straightforward.
Unfortunately, graphs don’t have this same structure. A graph is defined by its set of nodes and edges—the nodes and edges do not have any particular order. We can’t build a graph in a unique way by adding on nodes and edges because any given graph could be built up in multiple different ways. And so we can’t break the graph up in a unique way. We can’t pattern match on the graph. Our code is awkward.
Inductive Graphs
Inductive graphs are graphs that we can view as if they were a normal inductive data type. We can split a graph up and recurse over it, but this isn’t a structural operation like it would be for lists and, more importantly, it is not canonical: at any point, many different graph decompositions might make sense.
We can always view a graph as either empty or as some node, its edges and the rest of the graph. A node together with its incoming and outgoing edges is called a context; the idea is that we can split a graph up into a context and everything else, just like we can split a list up into its head element and everything else.
Conceptually, this is as if we defined a graph using two constructors, Empty and :& (in infix syntax):
The actual graph view in fgl is a bit different and supports node and edge labels, which I’ve left out for simplicity. The fundamental ideas are the same.
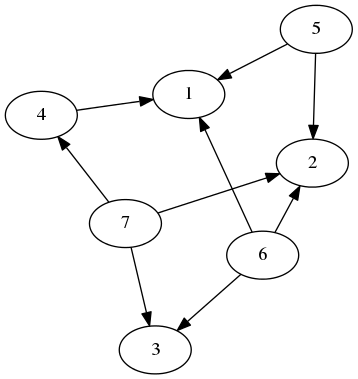
Consider a small example graph:
Just a random graph.
We could decompose this graph into the node 1, its context and the rest of the graph:
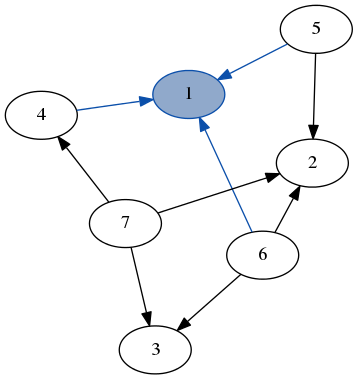
(Context [4,5,6] 1 []) :& graph our graph decomposed into the node 1, its edges to 4, 5 and 6 as well as the rest of the graph.
However, we could just as easily decompose the same example graph into node 2 and the rest:
(Context [5,6,7] 2 []) :& graph another equally valid way to decompose the same graph.
This means we can’t use this algebraic definition directly. Instead the actual graph type is abstract and we just view it using contexts, like above. Unlike normal pattern matching, viewing an abstract type is not necessarily the inverse of constructing it.
We accomplish this by using a matching function that takes a graph and returns a context decomposition. Since there is no “natural” first node to return, the simplest matching function matchAny returns an arbitrary (implementation defined) decomposition:
matchAny ::Graph-> (Context, Graph)
In fgl, Context is just a tuple with four elements: incoming edges, the node, the node label and outgoing edges.
The simplest way to use matchAny is with a case expression. Here’s the moral equivalent of head for graphs:
Pattern matching with case like this is a bit awkward. Happily, we can get much nicer syntax using ViewPatterns, which allow us to call functions inside a pattern. Here’s a prettier version of ghead which does exactly the same thing:
All my functions from now on will use ViewPatterns because they lead to nicer, more compact and more readable code.
Since the exact node that matchAny returns is implementation defined, it’s often inconvenient. We can overcome this using match, which matches a specific node.
match ::Node->Graph-> (MaybeContext, Graph)
If the node is not in the graph, we get a Nothing for our context. This function can also be used as a view pattern:
foo (match node -> (Just context, graph)) =...
This makes it easy to do directed traversals of the graph: we can “travel” to the node of our choice.
A Real Example
All functions in fgl are actually specified against a Graph typeclasses rather than a concrete implementation. This typeclass mechanism is great since it allows multiple implementations of inductive graphs. Unfortunately, it also breaks type inference in ways that are sometimes hard to track down so, for simplicity, we’ll just use the provided implementation: Gr. Gr n e is a graph that has nodes labeled with n and edges labeled with e.
Map
The “Hello, World!” of recursive list functions is map, so lets start by looking at a version of map for graphs. The idea is to apply a function to every node label in the graph.
For reference, here’s list map:
map :: (a -> b) -> [a] -> [b]map f [] = []map f (x:xs) = f x :map f xs
First, we have a base case for the empty list. Then we decompose the list, apply the function to the single element and recurse on the remainder.
The map function for graph nodes looks very similar:
mapNodes :: (n -> n') ->Gr n e ->Gr n' emapNodes _ g | Graph.isEmpty g = Graph.emptymapNodes f (matchAny -> ((in', node, label, out), g)) = (in', node, f label, out) & mapNodes f g
The base case is almost exactly the same. For the recursive case, we use matchAny to decompose the graph into some node and the rest of the graph. For the node, we actually get a Context which contains the incoming edges (in'), outgoing edges (out), the node itself (node) as well as the label (label). We just want to apply a function to the label, so we pass the rest of the context through unchanged. Finally, we recombine the graph with the & function, which is the graph equivalent of : for lists. (Although note that it is not a constructor but just a function!)
Since we used matchAny, the exact order we map over the graph is not defined! Apart from that, the code feels very similar to programming against normal Haskell data types and characterizes fgl in general pretty well.
DFS
Our maze algorithm is going to be a randomized depth-first search. We can first write a simple, non-random DFS and then go from that to our maze algorithm. That’s one of my favorite ways to implement more difficult algorithms: start with something really simple and iterate.
The basic DFS is actually pretty similar to mapNodes except that we’re going to build up a list of visited nodes as we go along instead of building a new graph. It’s also a directed traversal unlike the undirected map.
The first version of our DFS will take a graph and traverse it starting from a given node, returning a list of the nodes visited in order. Here’s the code:
dfs ::Graph.Node->Gr a b -> [Node]dfs start graph = go [start] graphwhere go [] _ = [] go _ g | Graph.isEmpty g = [] go (n:ns) (match n -> (Just c, g)) = n : go (Graph.neighbors' c ++ ns) g go (_:ns) = go ns g
The core logic is in the helper go function. It takes two arguments: a list, which is the stack of nodes to visit, and the remainder of the graph.
The first two lines of go are the base cases. If we either don’t have any more nodes on the stack or we’ve run out of nodes in the graph, we’re done.
The recursive cases are more interesting. First, we get the node we want to visit (n) from our stack. Then, we use that to direct our match with the match n function. If this succeeds, we add n to our result list and push every neighbor of n to the stack. If the match failed, it means we visited that node already, so we just ignore it and recurse on the rest of the stack.
We find the neighbors of a node using the neighbors' function which gets the neighbors of a context. In fgl, functions named with a ' typically act on contexts.
The important idea here is that we don’t need to explicitly keep track of which nodes we’ve visited—after we visit a node, we always recurse on the rest of the graph which does not contain it. This sort of behavior is common to a bunch of different graph algorithms making this a very useful pattern.
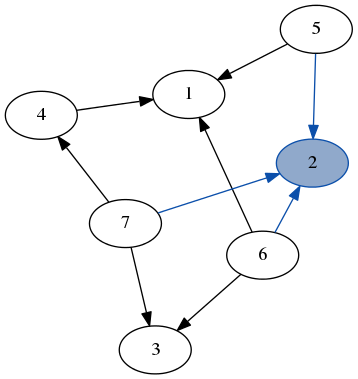
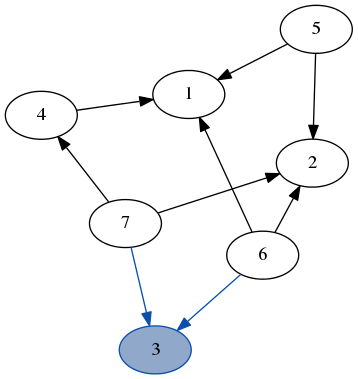
Here’s a quick demo of dfs running over the example graph from earlier. Note how we don’t need to keep track of which nodes we’ve visited because we always recurse on the part of the graph that only has unvisited nodes.
stack: [7, 6]
result: [3]
stack: [4, 2, 6]
result: [3, 7]
stack: [1, 2, 6]
result: [3, 7, 4]
stack: [6, 5, 2, 6]
result: [3, 7, 4, 1]
stack: [2, 5, 2, 6]
result: [3, 7, 4, 1, 6]
stack: [5, 5, 2, 6]
result: [3, 7, 4, 1, 6, 2]
stack: [5, 2, 6]
result: [3, 7, 4, 1, 6, 2, 5]
Often—like for generating mazes—we don’t care about which node to start from. This is where ghead comes in since it selects an arbitrary node for us! The only thing to consider is that ghead will fail on an empty graph.
EDFS
dfs gives us nodes in the order that they were visited. But for mazes, we really care about the edges we followed rather than just nodes. So lets modify our dfs into an edfs which returns a list of edges rather than a list of nodes. In fgl, an edge is just a tuple of two nodes: (Node, Node).
The modifications from our original dfs are actually quite slight: we keep a stack of edges instead of a stack of nodes. This requires modifying our starting condition:
Since we’re storing edges on our stack, we can’t just put the start node directly on there. Instead, we just match on it and start with its edges on the stack.
We need the extra call to normalize because we’re treating our edges as if they were undirected and we need to make sure that the two nodes that define an edge always appear in the same order. It just goes through the edges and swaps the nodes if they’re in the wrong order.
The other change was for the recursive case, where we push edges onto the stack instead of nodes:
go ((p, n) : ns) (match n -> (Just c, g)) = (p, n) : go (neighborEdges' c ++ ns) g
neighborEdges is just a helper function that returns all the incoming and outgoing edges from a context. (In the actual code, I called it lNeighbors because it actually returns labeled edges.
Randomness
The final change we need to generate a maze is adding randomness. We want to shuffle the list of neighboring edges before putting it on the stack. We’re going to use the MonadRandom class, which is compatible with a bunch of other monads like IO. I wrote a naïve O(n²) shuffle:
shuffle ::MonadRandom m => [a] -> m [a]
Given this, we just need to modify edfs to use it which requires lifting everything into the monad.
edfsR ::MonadRandom m =>Graph.Node->Gr n e -> m [(Node, Node)]edfsR start (match start -> (Just ctx, graph)) = liftM normalize $$ go (lNeighbors' ctx) graphwhere go [] _ =return [] go _ g | Graph.isEmpty g =return [] go ((p, n):ns) (match n -> (Just c, g)) =do edges <- shuffle $$ neighborEdges' c liftM ((p, n) :) $$ go (edges ++ ns) g go (_:ns) g = go ns g
The differences are largely simple and very type-directed: you have to add some calls to return and liftM, but you get some nice type errors that tell you where to add them. The only other change is using shuffle which is straightforward with do-notation.
For something that’s supposed to be awkward in functional programming, I think the code is actually pretty neat and easy to follow!
Since we used the MonadRandom class, we can use edfsR with any type that provides randomness capabilities. This includes IO, so we can use it directly from GHCi, which is quite nice. We could also run it in a purely deterministic way by providing a seed if we wanted.
Mazes
We have a random DFS that gives us a list of edges—the core of the maze generation algorithm. However, it’s difficult to go from a set of edges to drawing a maze. The final pieces of the puzzle are labeling the edges in a way that’s convenient to draw and generating the graph for the initial grid.
This is the first place where we’re going to use edge labels. Each edge represents a wall and we need enough information to draw it. We need to know the walls location and its orientation (either horizontal and vertical). For simplicity, we will locate the walls by the location of the cell either below or to the right of the wall as appropriate for its direction. Here are the relevant types:
dataOrientation=Horizontal|Verticalderiving (Show, Eq)dataWall=Wall (Int, Int) Orientationderiving (Show, Eq)typeGrid=Gr () Wall-- () means no node labels needed
Next, we need to build the starting graph: a maze with every single wall present. We can assemble it with the mkGraph function which takes a list of nodes and a list of edges. We want to label each edge with its location and orientation. There’s likely a better way to do all this, but for now I take advantage of the fact that Node is just an alias for Int:
grid ::Int->Int->Gridgrid width height = Graph.mkGraph nodes edgeswhere nodes = [(node, ()) | node <- [0..width * height -1]] edges = [(n, n', wall n Vertical) | (n, _) <- nodes, (n, _) <- nodes, n - n' ==1&& n `mod` width /=0 ]++ [(n, n', wall n Horizontal) | (n,_) <- nodes, (n',_) <- nodes, n - n' == width ] wall n =let (y, x) = n `divMod` width inWall (x, y)
A 3 × 3 grid. The edges are labeled with an (x, y) position and either Horizontal (—) or Vertical (|).
Running edfsR over a starting maze will give us the list of walls that were knocked down—they’re the ones we don’t want to draw. We can easily go from this to the compliment list of walls to draw using the list different operator \\\\ from Data.List:
Since a grid is always going to have nodes, we can use ghead safely.
This produces a list of edges to draw from the graph. To actually draw them, we would start by looking their labels up in the grid and then use the position and orientation to figure out the walls’ absolute positions. (My actual implementation keeps track of edge labels as it does the DFS.)
All of the drawing code is in Draw.hs and uses cairo for the actual drawing. Cairo is a C library that provides something very similar to an HTML Canvas but for GtK; it can also output images. If you just want to play around with the mazes, you can draw one to a png with:
genPng defaults "my-maze.png"4040
A large 40 × 40 maze with all the default drawing settings.
More Fun
We now have a basic maze generating system using inductive graphs and randomness. If you want to play around with the code a bit, there are two interesting ways to extend this code: generating mazes from other shapes and using different graph algorithms.
Other Shapes
Our system always assumes that mazes are generated from a grid of cells. However, the actual graph code doesn’t care about this at all! The grid-specific parts are just the starting graph (ie grid 40 40) and the drawing code.
A fun challenge is to look at what mazes over other sorts of graphs look like. Try writing a maze generator based on tiled hexagons, polar rectangles or even arbitrary (maybe random?) plane tilings. Or try to generate mazes in 3D!
Other Algorithms
Apart from modifying the graph, we can also modify our traversal. Play around with the DFS code: for example, you can substitute in a biased shuffle and get other shapes of mazes. If you make the shuffle more likely to choose horizontal walls than vertical ones, you will get a maze with longer vertical passages and shorter horizontal ones. How else can you change the DFS?
Randomized DFS is a nice algorithm for generating mazes because it’s simple and produces aesthetically pleasant mazes. But it’s not the only possible algorithm. You could take some other algorithms that produce spanning trees and randomize those.
One particular trick is to take an algorithm for generating minimum spanning trees, and apply it to a graph with random edge weights. The two common minimum spanning tree algorithms are Prim’s algorithm and Kruskal’s algorithm—implementing those is a good Haskell exercise and will produce subtly different looking mazes. Take a look through Minimum Spanning Tree Algorithms on Wikipedia for more inspiration.
I think this code is a great example of how, once you’ve learned a bit, many tasks in functional programming are easier than they may seem at first. Starting from the right abstractions, working with graphs or randomness need not be difficult, even in a purely functional language like Haskell.
Ultimately, this is a good exercise both for becoming a better Haskell programmer and for realizing just how versatile the language can be.

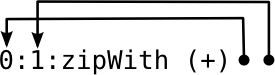





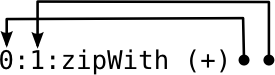

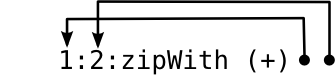






 stack:
stack: 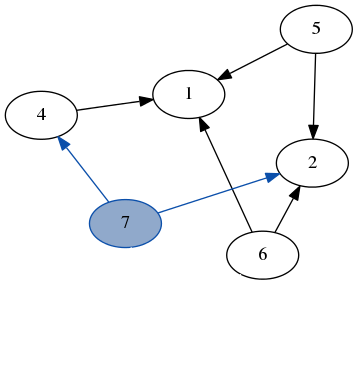 stack:
stack: 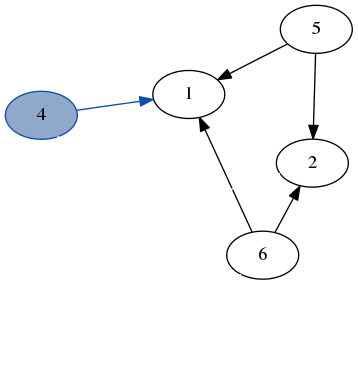 stack:
stack: 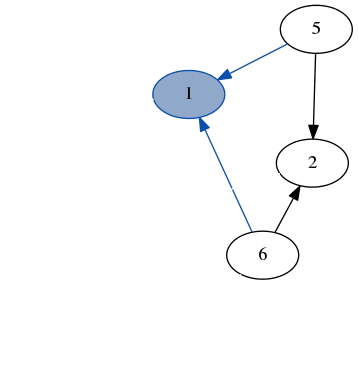 stack:
stack: 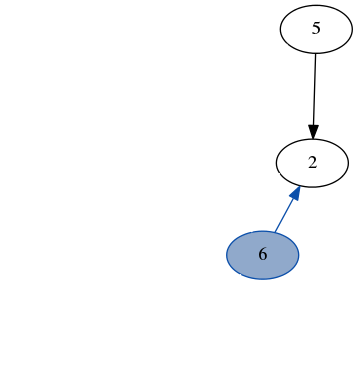 stack:
stack: 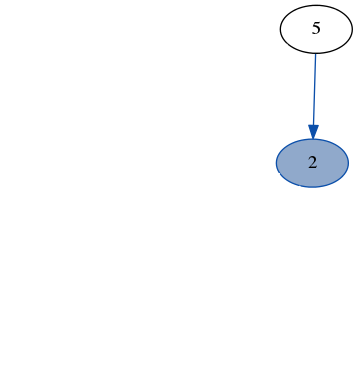 stack:
stack:  stack:
stack: